Les organisations voient leurs données se développer à un rythme accéléré. Et alors que les équipes élaborent des solutions avec les bons outils, les données se retrouvent souvent dans des endroits, des formats et même des plateformes cloud différents. Ces données de plus en plus distribuées conduisent à des silos, et les silos de données présentent leurs propres risques et problèmes. Pourtant, ces données ont une grande valeur analytique qui peut répondre aux nouveaux cas d’usages client toujours plus exigeants.
Pour évoluer dans un monde numérique en pleine croissance, les entreprises doivent éliminer les silos de données et permettre de nouveaux cas d’usages analytiques, quel que soit l’endroit où les données sont stockées ou leur format.
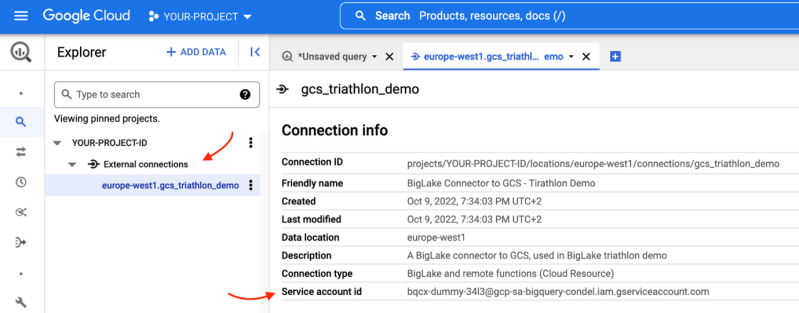
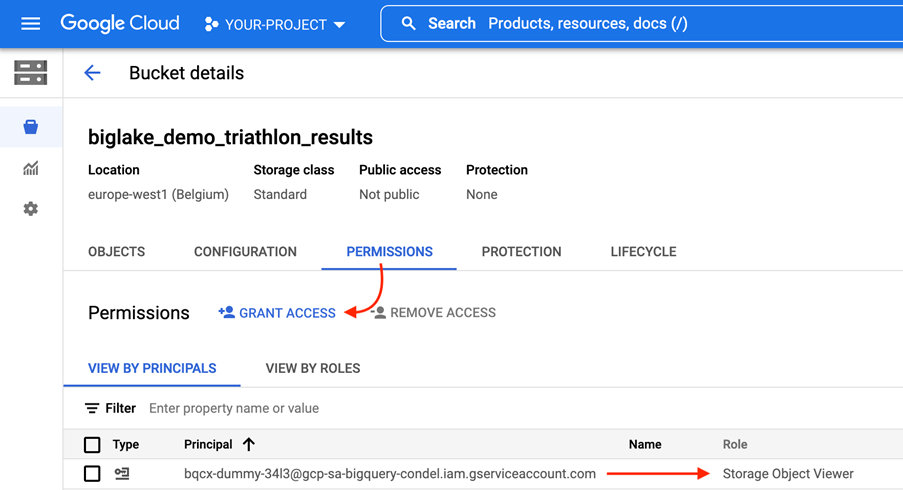
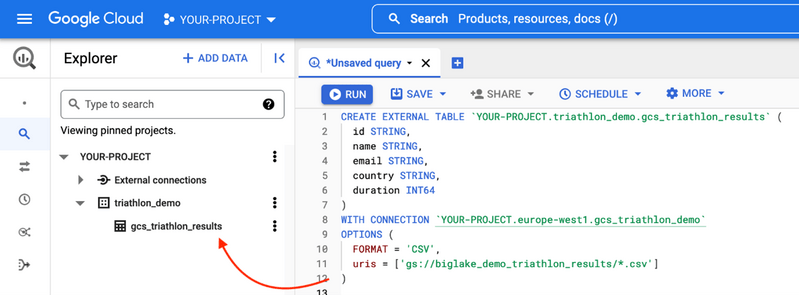
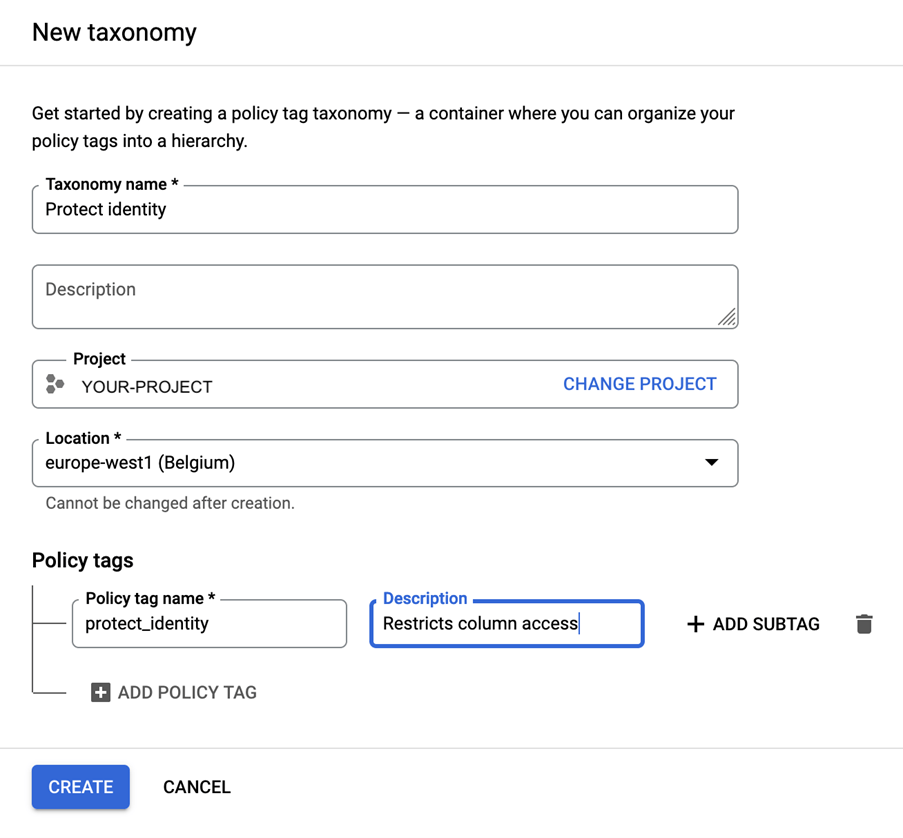
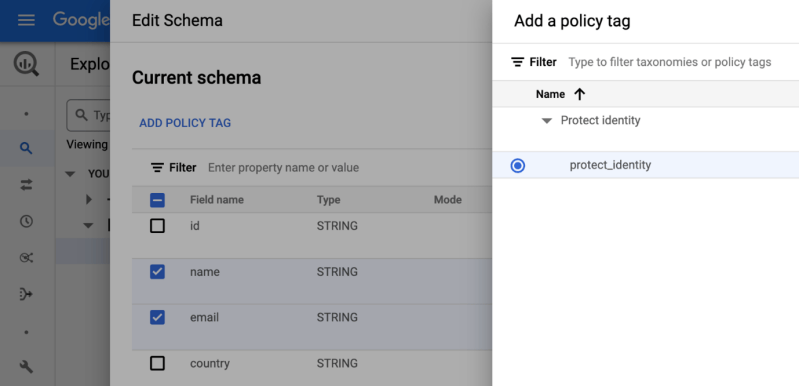
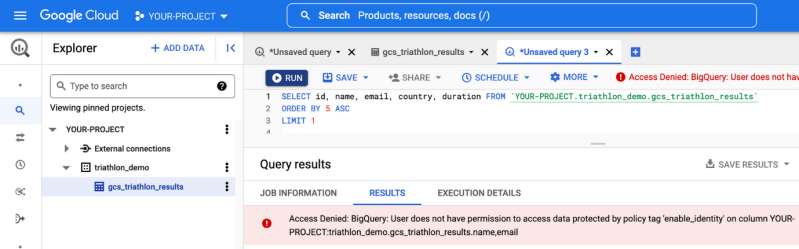
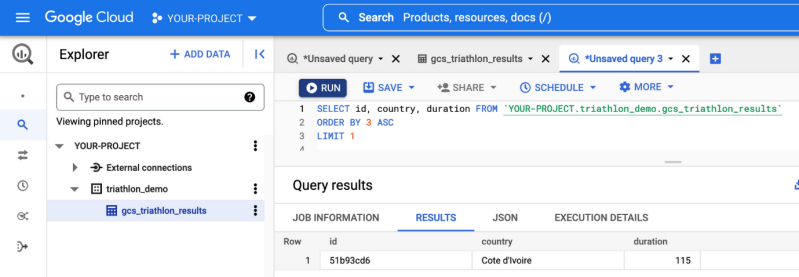
Pour combler ce fossé entre les données et la valeur ajoutée, Google a introduit une nouvelle fonctionnalité : BigLake. BigLake s’appuie sur les années d’innovation de BigQuery, c’est un moteur de stockage qui unifie les data lakes et les data warehouses, tout en offrant un contrôle d’accès à haute granularité, une accélération des performances sur le stockage multi-cloud et la prise en charge des formats de fichiers ouverts.