Les organisations voient leurs données se développer à un rythme accéléré. En hoewel de medewerkers oplossingen ontwikkelen met de beste hulpmiddelen, bevinden de gegevens zich vaak op verschillende locaties, in verschillende formaten en zelfs op verschillende cloudplatforms. Deze steeds verder verspreide gegevens leiden tot silo's, en deze silo's van gegevens brengen hun eigen risico's en problemen met zich mee. Deze gegevens hebben echter een grote analytische waarde die kan inspelen op nieuwe gevallen van klantgebruik die steeds veeleisender worden.
Om te evolueren in een digitale wereld die volop in ontwikkeling is, moeten bedrijven de silo's van gegevens verwijderen en nieuwe gevallen van analytisch gebruik mogelijk maken, ongeacht de plaats waar de gegevens worden opgeslagen of hun formaat.
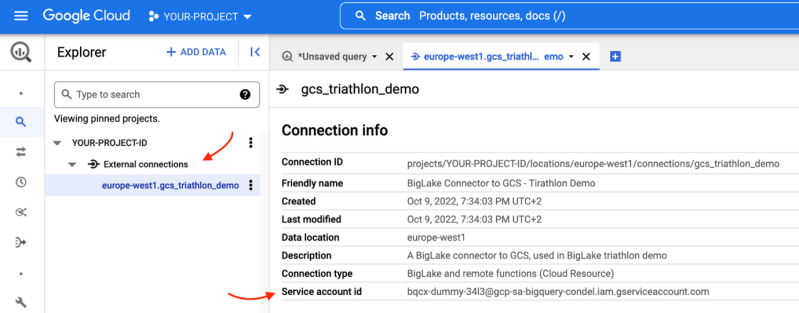
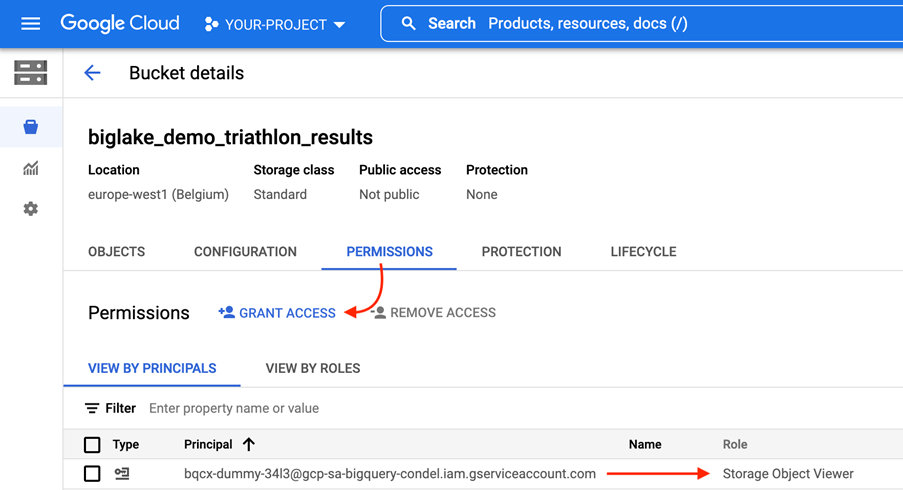
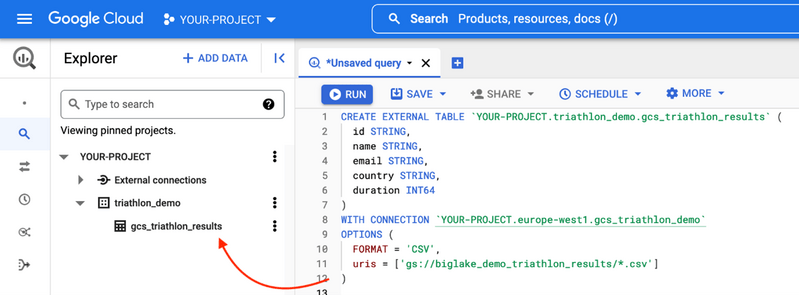
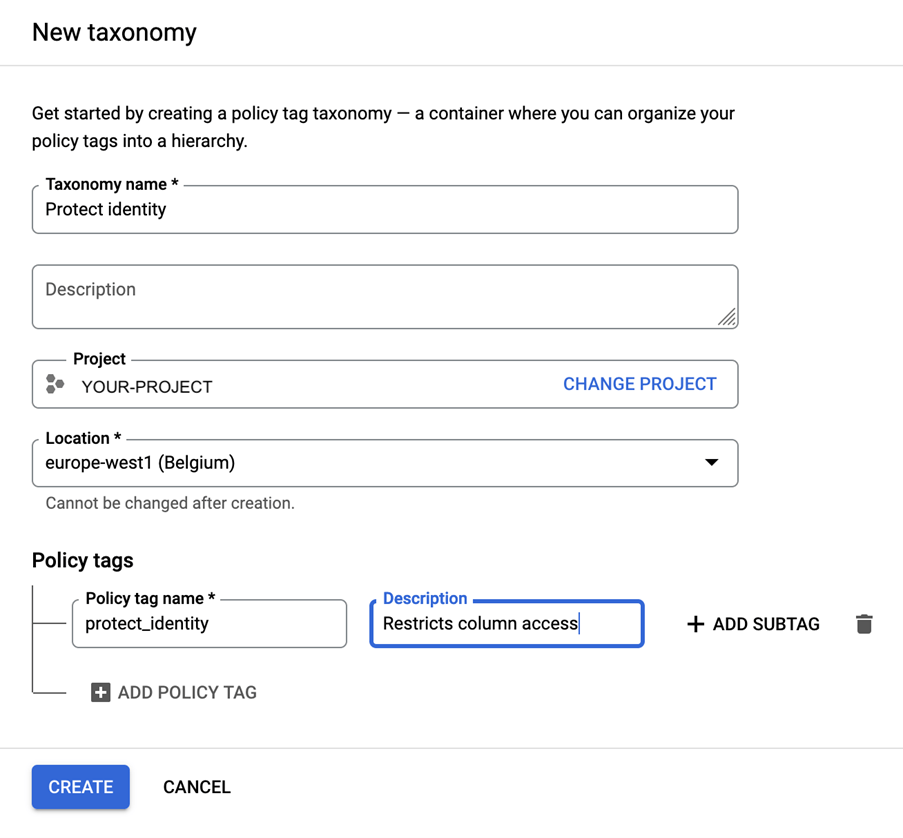
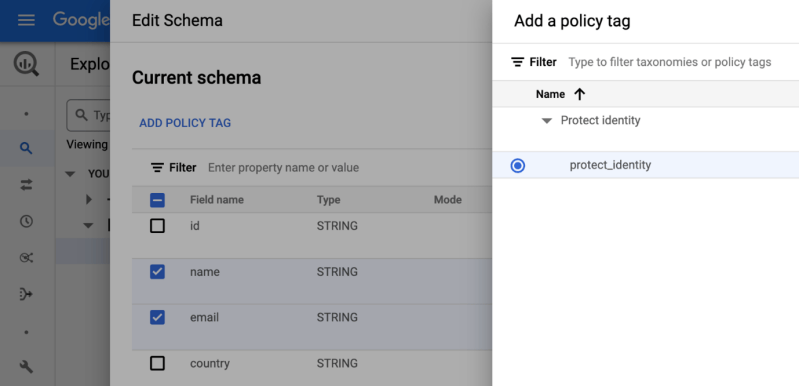
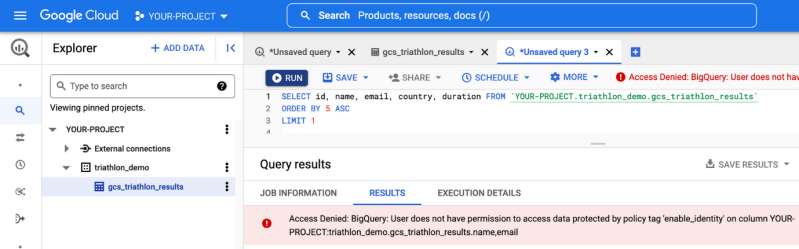
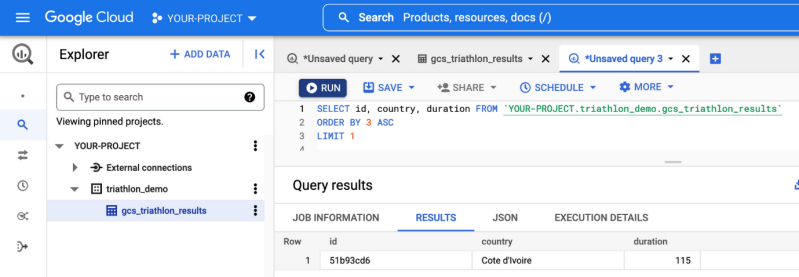
Om dit probleem tussen de gegevens en de toegevoegde waarde op te lossen, heeft Google een nieuwe functie geïntroduceerd: BigLake. BigLake is gebaseerd op de jaren van innovatie van BigQuery, het is een opslagmedium dat data lakes en datawarehouses verenigt, en tegelijkertijd een toegangscontrole op hoge granulariteit, een verbeterde prestatie bij multi-cloud opslag en de verwerking van oude bestandsformaten biedt.