


Qui est VOO ?
VOO est le nom d’un opérateur télécom belge. Il est principalement actif dans les régions de Wallonie et de Bruxelles. Fournissant à ses clients des services de câble, de téléphone et d’Internet, VOO est orienté vers la clientèle et la technologie.
Vous et toute votre famille pouvez profiter d’un Internet haut débit super rapide, d’une riche mine de contenus télévisés et d’un service mobile et fixe généreux grâce aux produits et services innovants de VOO. Il s’agit d’un opérateur télécom belge que les experts de Lucy ont aidé dans sa transformation numérique.
Enjeux
- Augmenter considérablement la connaissance des clients pour accélérer l’acquisition et améliorer la fidélité et la rétention.
- Soutenir la transformation numérique en offrant une vision unifiée du client et de son comportement.
- Répondre aux nouveaux défis de la conformité (GDPR)
- Réduire radicalement le coût total de possession des environnements de données (4 environnements de BI différents + 3 clusters Hadoop avant la transformation).
- Introduire une gouvernance des données à l’échelle de l’entreprise et résoudre le problème de la BI fantôme (plus de 25 ETP du côté de l’entreprise pour traiter les données).
La solution
Les experts de Lucy ont mené une étude rapide, analysant tous les aspects de la transformation et abordant à la fois le défi organisationnel (rôles et responsabilités, équipes et compétences, processus, gouvernance) et le défi technique (scénarios architecturaux holistiques, allant du cloud hybride aux solutions full cloud en mode PaaS).
Sur la base des résultats de l’étude, nous avons déployé une plateforme de données basée sur le cloud, à l’échelle de l’entreprise. Elle combine les processus de BI traditionnels avec des capacités analytiques avancées. Nous avons redéfini l’organisation des données et les processus associés et introduit la gouvernance des données au niveau de l’entreprise.
Le coût total de possession est tombé à moins de 30 % de ce qu’il était auparavant. L’agilité et les capacités se sont considérablement améliorées.
Une plateforme de données basée sur le cloud, à l’échelle de l’entreprise, alimentée par AWS
Architecture basée sur les services de données clés d’AWS
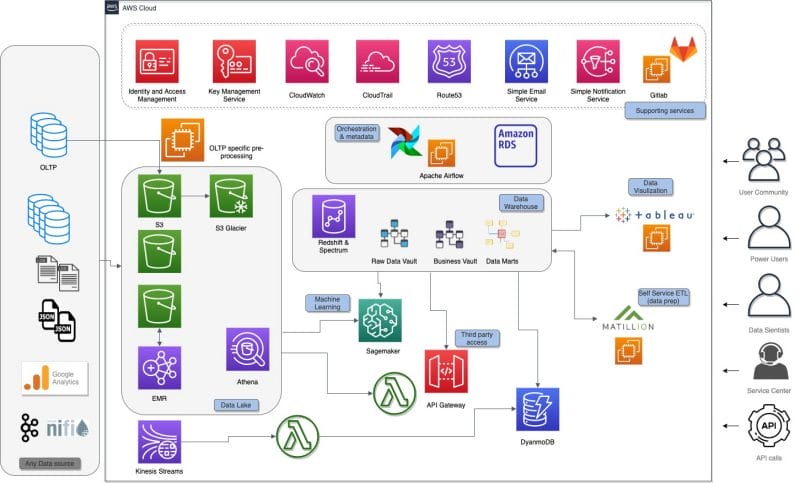
Data Lake
Amazon S3 est utilisé pour la couche centrale d’entrée et pour assurer la persistance à long terme.
Certains fichiers de données sont prétraités sur Amazon EMR. Les clusters EMR sont créés à la volée plusieurs fois par jour. Les clusters traitent uniquement les nouvelles données qui arrivent dans S3. Une fois les données traitées et persistées dans un format Apache Parquet optimisé pour l’analyse, le cluster est détruit. Le cryptage et la gestion du cycle de vie sont activés sur la plupart des buckets S3 pour répondre aux exigences de sécurité et de rentabilité. Les données sont actuellement stockées dans le lac de données. Amazon Athena est utilisé pour créer et maintenir un catalogue de données et explorer les données brutes dans le Data Lake.
Data Warehouse
L’entrepôt de données fonctionne sur Amazon Redshift, en utilisant les nouveaux nœuds RA3 et suit la méthodologie Data Vault 2.0. Les objets Data Vault sont très standardisés et ont des règles de modélisation strictes, ce qui permet un haut niveau de standardisation et d’automatisation. Le modèle de données est généré à partir des métadonnées stockées dans une base de données Amazon RDS Aurora.
Le moteur d’automatisation lui-même est construit sur AWS Step Functions et AWS lambda.
DynamoDB
Amazon DynamoDB est utilisé pour des cas d’utilisation spécifiques où les applications web ont besoin de temps de réponse inférieurs à la seconde. L’utilisation de la capacité variable de lecture/écriture de DynamoDB permet de provisionner la capacité de lecture haute performance, plus coûteuse, uniquement pendant les heures de bureau, lorsqu’une faible latence et un temps de réponse rapide sont nécessaires. Ces mécanismes, qui reposent sur l’élasticité des services AWS, sont utilisés pour optimiser la facture mensuelle d’AWS.
Machine Learning
Une série de modèles prédictifs ont été mis en œuvre, allant d’un modèle classique de prédiction de désabonnement à des cas d’utilisation plus avancés. Amazon SageMaker a été utilisé pour construire, former et déployer les modèles à l’échelle, en exploitant les données disponibles dans le Data Lake (Amazon S3) et l’entrepôt de données (Amazon Redshift).
Et bien plus encore !
Mentions dans la presse
En savoir plus sur ce projet disruptif mené avec succès par Micropole ? Lisez l’article suivant !
Cas d'usage




