Delta Lake a été publié en avril 2019 par Databricks. Delta Lake est une couche au-dessus d’un data Lake, qui fournit des capacités ACID, garantissant la qualité, la fiabilité et la cohérence des données.
Au cours d’un processus, les transactions sont stockées dans un fichier de log; cela vous aide à restaurer vos données en cas de problème.
Quelles sont les nouvelles fonctionnalités de delta Lake 2.0 ?
Lors du sommet de 2022, Databricks a révélé plusieurs nouvelles fonctionnalités.
– Change Data Feed : permet de suivre les changements de lignes entre les versions d’une table delta.
– Suppression de colonnes : vous pouvez supprimer une colonne avec la commande “DROP COLUMN”.
– Multi-cluster writes (S3) : écrire sur une table à partir de plusieurs clusters simultanément ne corrompt pas la table ; cette fonctionnalité existe déjà sur Azure.
– Z-order : permet d’optimiser l’organisation des fichiers d’une table Delta; vous verrez cette fonctionnalité en détail plus loin dans cet article.
D’autres améliorations ont été apportées à des fonctionnalités existantes, notamment pour le Data skipping en utilisant les statistiques de colonnes : le Data skipping permet d’augmenter les performances lors des opérations de lecture. Lors de l’écriture des fichiers, le delta log stockera la valeur maximale et minimale de chaque colonne du fichier. Cela permet d’accélérer la réponse de la lecture en ne tenant pas compte des fichiers inutiles. Cela fonctionne très bien si vous avez un petit intervalle de valeurs dans chaque fichier. Et c’est là que le Z-order entre en jeu !
Z-order
Databricks a introduit “Optimize Z-order”. Il colocalise les informations des colonnes dans le même ensemble de fichiers. Ces fichiers sont triés et regroupés selon la colonne spécifiée. Lorsqu’on lance une recherche, seuls les fichiers avec les valeurs de requête sont analysés.
Ci-dessous, la table serviceTbl n’est pas ordonnée. Une requête telle que “Select * from serviceTbl = ‘IoT hub'”, peut analyser tous les fichiers. La mise en œuvre de Z-order demandera à la table d’optimiser le balayage pour notre requête.
Lorsque la table est ordonnée, la recherche de données est plus rapide.
Le comportement de Z-order est très similaire à celui de l’index cluster de SQL Server : plusieurs colonnes peuvent être spécifiées. Vous pouvez choisir les colonnes Z-order en fonction des modèles de requêtes. Z-order va alors réduire le nombre de fichiers pour améliorer les performances de la lecture de la requête. Voyons cela en pratique.
Nous allons utiliser une table de vente delta avec 2 milliards de lignes.
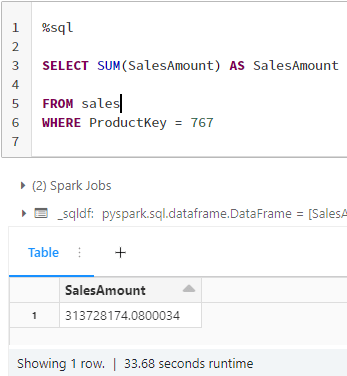
Exécutons la première requête o
Le résultat est obtenu en 33 secondes. En fonction du modèle de requête, vous pouvez modifier la structure du fichier avec Z-order.
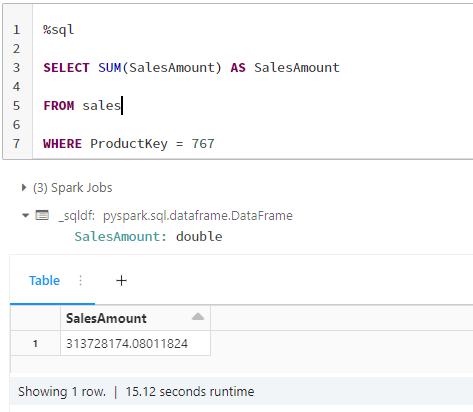
La table delta est reconstruite sur base de la clause Z-order BY. Vous obtenez 121 fichiers au lieu de 342, ce qui signifie moins de fichiers à lire. La rangée de valeurs de chaque fichier est plus petite. Ces changements de structure ont un impact considérable et améliorent les performances de notre requête.
Le résultat de la requête sort au bout de 15 secondes. Vous gagnez 18 secondes sur la même requête !
Pourquoi est-ce plus rapide ?
Comme nous l’avons vu, Delta Lake enregistre les valeurs maximale et minimale de chaque colonne de chaque fichier dans le journal Delta, ce qui accélère la lecture des requêtes. L’ajout de Z-order au prédicat (clause “where”) regroupera vos données et rendra le data skipping plus efficace. Il faut créer Z-order sur une colonne à cardinalité élevée.
Ce dont vous devez vous souvenir lorsque vous implémentez Z-order :
– Sur les colonnes à cardinalité élevée – Utilisez Z-order sur les colonnes de prédicat – Plusieurs colonnes peuvent être spécifiées – Si le modèle de requête change, mettez à jour Z-order. – La commande Vacuum est nécessaire pour nettoyer le journal delta de la structure précédente des fichiers.
Conclusion
Delta Lake s’améliore continuellement en combinant le meilleur des data warehouses traditionnels et le meilleur des data lakes. Avec Z-order, vous avez pu constater à quelle vitesse vous pouvez améliorer vos performances. Change Data Feed (CDF) permet à Delta Lake de suivre les changements au niveau des lignes, ce qui améliore les performances.
Faites-nous savoir si vous souhaitez avoir plus d'informations sur CDF !
Micropole Belgium, part of the Talan Group, regularly shares industry insights and company updates to keep our community informed about digital transformation and technology trends.
Whether you’re a client interested in our topics or a member of the press seeking expert commentary, feel free to reach outdirectly.