Delta Lake is gepubliceerd in april 2019 door Databricks. Delta Lake is een couche au-dessus d'un data Lake, die voorziet in ACID-capaciteiten die de kwaliteit, betrouwbaarheid en samenhang van de gegevens garanderen.
Au cours d'un processus, les transactions sont stockées dans un fichier de log; cela vous aide à restaurer vos données en cas de problème.
Wat zijn de nieuwe functies van delta Lake 2.0?
Lors du sommet de 2022, Databricks a révéléé plusieurs nouvelles fonctionnalités.
- Change Data Feed: maakt het mogelijk om de veranderingen in de lijnen tussen de versies van een tabel delta te volgen.
- Kolommen onderdrukken: u kunt een kolom onderdrukken met het commando "DROP COLUMN".
- Multi-cluster schrijfopdrachten (S3): schrijfopdrachten in een tabel vanuit meerdere clusters tegelijk corrumperen de tabel niet; deze functie bestaat al in Azure.
- Z-order : hiermee kunt u de organisatie van bestanden in een tabel Delta optimaliseren; lees meer over deze functie in dit artikel.
Er zijn nog andere verbeteringen aangebracht aan bestaande functies, met name voor Data skipping door gebruik te maken van statistieken van kolommen: Data skipping maakt het mogelijk om de prestaties tijdens lezingen te verbeteren. Tijdens het schrijven van bestanden slaat de delta log de maximale en minimale waarde van elke kolom in het bestand op. Dit versnelt de respons van de lezing en houdt geen rekening met ongebruikte bestanden. Cela fonctionne très bien si vous avez un petit intervalle de valeurs dans chaque fichier. Et c'est là que le Z-order entre en jeu!
Z-order
Databricks heeft "Z-order optimaliseren" geïntroduceerd. Deze optimaliseert de informatie van de kolommen in hetzelfde ensemble van bestanden. Deze bestanden worden onderzocht en gegroepeerd op basis van de gespecificeerde kolom. Wanneer een onderzoek wordt gestart, worden alleen de bestanden met de vereiste waarden geanalyseerd.
Ci-dessous, la table serviceTbl n'est pas ordonnée. Een verzoek zoals "Selecteer * uit serviceTbl = 'IoT hub'" kan alle bestanden analyseren. De werking van Z-order vereist dat de tabel de balayage voor dit verzoek optimaliseert.
Als de tabel geordend is, verloopt het zoeken naar gegevens sneller.
De werking van de Z-order is vergelijkbaar met die van het indexcluster van SQL Server: meerdere kolommen kunnen worden gespecificeerd. U kunt de Z-order-kolommen kiezen op basis van de modelvereisten. Met Z-order kunt u het aantal bestanden verminderen om de prestaties van de lezing van het verzoek te verbeteren. Probeer dit in de praktijk.
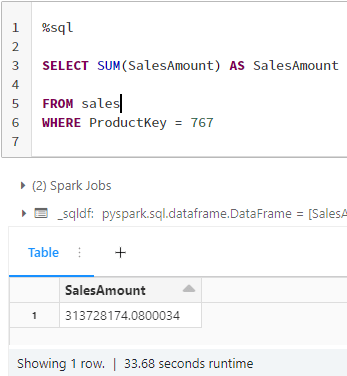
We maken gebruik van een tabel met deltaverkopen met 2 miljoen lignes.
Voer de eerste aanvraag uit o
Het resultaat wordt binnen 33 seconden verkregen. En fonction du modèle de requête, vous pouvez modifier la structure du fichier avec Z-order.
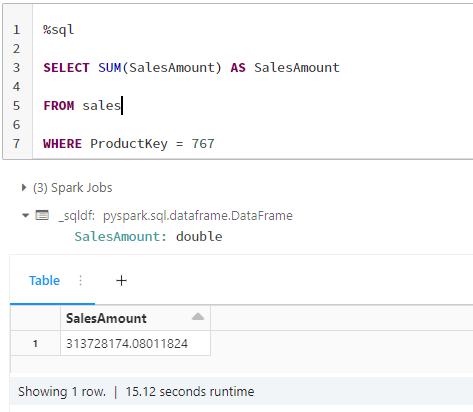
De tabel delta is opnieuw opgebouwd op basis van de clausule Z-order BY. Je krijgt 121 bestanden in plaats van 342, wat betekent dat er minder bestanden te lezen zijn. Het waardenbereik van elk bestand is kleiner. Deze veranderingen in de structuur hebben een aanzienlijke impact en verbeteren de prestaties van onze aanvraag.
Het resultaat van de aanvraag wordt na 15 seconden gesorteerd. U krijgt 18 seconden voor dezelfde aanvraag!
Waarom is dit zo snel?
Zoals we hebben gezien, registreert Delta Lake de maximale en minimale waarden van elke kolom van elk bestand in het dagboek Delta, wat de lezing van de aanvragen versnelt. Het toevoegen van een Z-order aan een prédicat (clausule "where") hergroepeert uw gegevens en maakt het overslaan van gegevens efficiënter. Je moet een Z-order aanmaken op een kolom met een hoge kardinaliteit.
Wat u niet mag vergeten als u Z-order geïmplementeerd hebt:
- Sur les colonnes à cardinalité élevée - Utilisez Z-order sur les colonnes de prédicat - Plusieurs colonnes peuvent être spécifiées - Si le modèle de requête change, mettez à jour Z-order. - La commande Vacuum est nécessaire pour nettoyer le journal delta de la structure précédente des fichiers.
Conclusie
Delta Lake verbetert voortdurend en combineert het beste van traditionele datawarehouses met het beste van data lakes. Met Z-order kunt u vaststellen hoe snel u uw prestaties kunt verbeteren. Change Data Feed (CDF) biedt Delta Lake de mogelijkheid om wijzigingen op ligniveau te volgen, waardoor de prestaties verbeteren.
Laat het ons weten als u meer informatie wilt over CDF!
Micropole België, onderdeel van de Talan Group, deelt regelmatig inzichten uit de sector en bedrijfsupdates om onze community op de hoogte te houden van digitale transformatie en technologische trends.
Of u nu een klant bent die geïnteresseerd is in onze onderwerpen of een lid van de pers op zoek naar deskundig commentaar, voel u vrij om om contact op te nemenrechtstreeks.